This won Best Project for the Alignment Research Bootcamp Oxford
Refusal in Language Models Is Mediated by a Single Direction showed that the concept of refusal is encoded as a single direction in the residual stream of the model. Incapability is another concept, somewhat similar to refusal that models also encode. In this project, I investigate how these two concepts are mechanistically represented.
Executive Summary
What problem am I trying to solve?
I want to investigate how language models mechanistically represent the two distinct ways of saying “no”: through refusal behaviours and incapability behaviours. Refusal is when a model has the capability to do, but is harmful and thus goes against its guidelines. Incapability is when the model is tasked with something it can’t do, but isn’t harmful and has no ethical objections. Think of it as “I can’t do this, but if I could I would try to”. Examples of these are agentic tasks, such as “Fill up my car with fuel”.
I’m interested in exploring how refusal and incapability interact with each other and the behaviours they exhibit. I’m intrigued by questions such as does the model care about how it says “no”? Are these similar or distinct concepts? Can we find out how exactly they are encoded? and so on.
Tooling
For others who want to reference, I mostly used TransformerLens and Matplotlib for this project. SAELens was also used, but was fiddly and so I didn’t end up putting those results in here.
High Level Takeaways
I ran a few key experiments and found that:
- Incapability as a direction does exist like refusal.
- Incapability and refusal are encoded as distinct but related directions (geometrically and conceptually) in the model’s residual stream. The model learns to separate them at layers 10-15.
- The refusal direction aligns closely with principal components in later layers, while incapability shows less alignment
- Both directions can be intervened upon to alter model behaviour, with specific refusal and incapability tokens (like “sorry” and “impossible”) increasing in probability.
Key experiments
Does an incapability direction exist? I identified the refusal and incapability directions by comparing activations from harmful vs. harmless and incapable vs capable tasks respectively. When these directions were ablated, the model’s output changed more towards non-refusal and capability, which supports that the model encodes this target behaviour.
How similar is it to the refusal direction? I measured the angle between the incapability and refusal direction computed at each layer. We see that for the early layers, they are maximally distinct (~75°), and for the later layers they become less distinct (~50°). This suggests that these concepts once fully processed are somewhat similar.
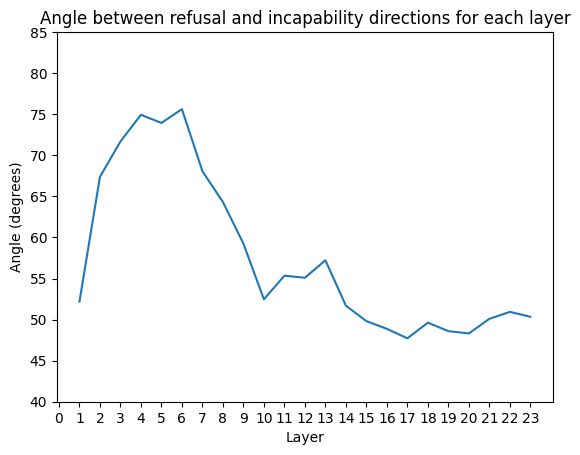 Figure 2: Angle between refusal and incapability directions throughout the layers of the model
Figure 2: Angle between refusal and incapability directions throughout the layers of the model
Are these distinct concepts?
I did PCA on the model activations, and this revealed distinct clusters for harmless, harmful and incapability prompts. The concepts start muddled in the early layers, and then become distinct. There is a clear separation in the middle to late layers - which provides good evidence that the model actually does distinguish between these refusal and incapability.
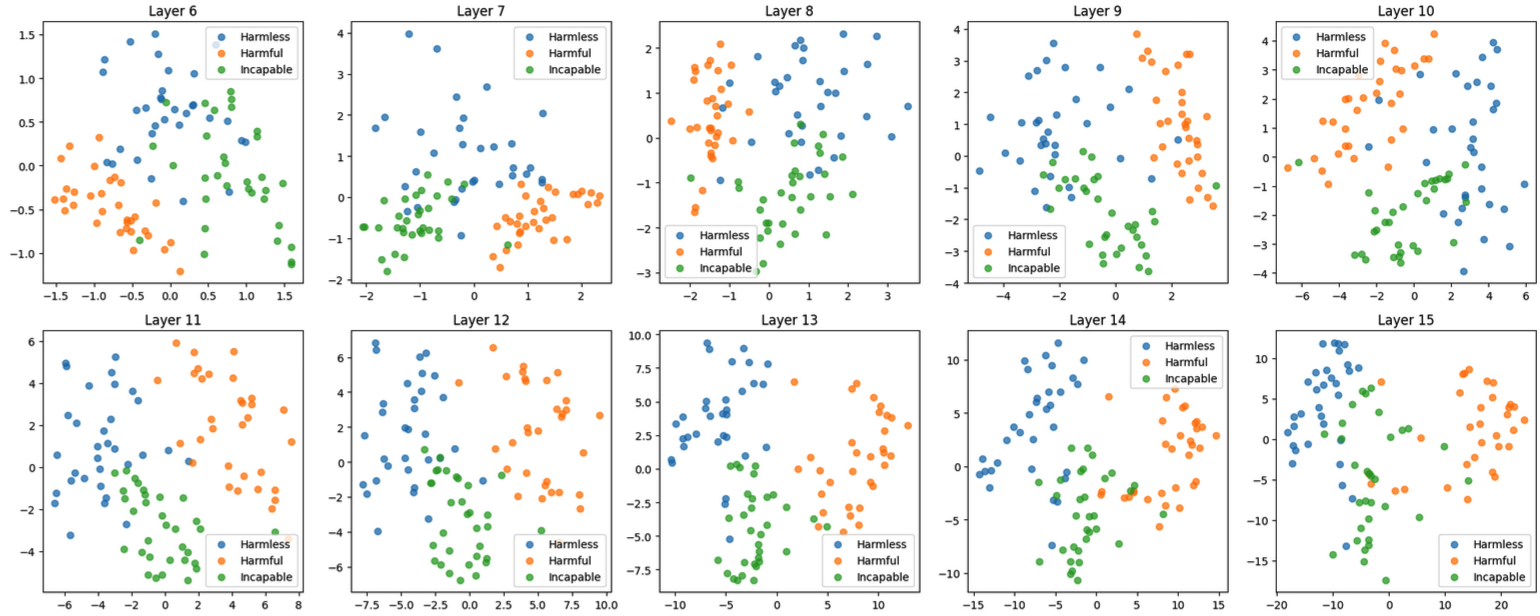 Figure 3: Distinct clusters for harmful, harmless and incapability concepts for layers 6-15 as a result of PCA
Figure 3: Distinct clusters for harmful, harmless and incapability concepts for layers 6-15 as a result of PCA
Can we validate how these directions are encoded? I derived directions from the PCA plots by taking the difference of the means from the clusters, and compared them to the actual refusal and incapability directions. For refusal, the PCA derived directions are similar, which is evidence that the refusal direction is primarily represented by the first 2 principal components. This isn’t the same for the incapability though. This suggests that incapability might not simply be represented by incapable - capable (aka harmless).
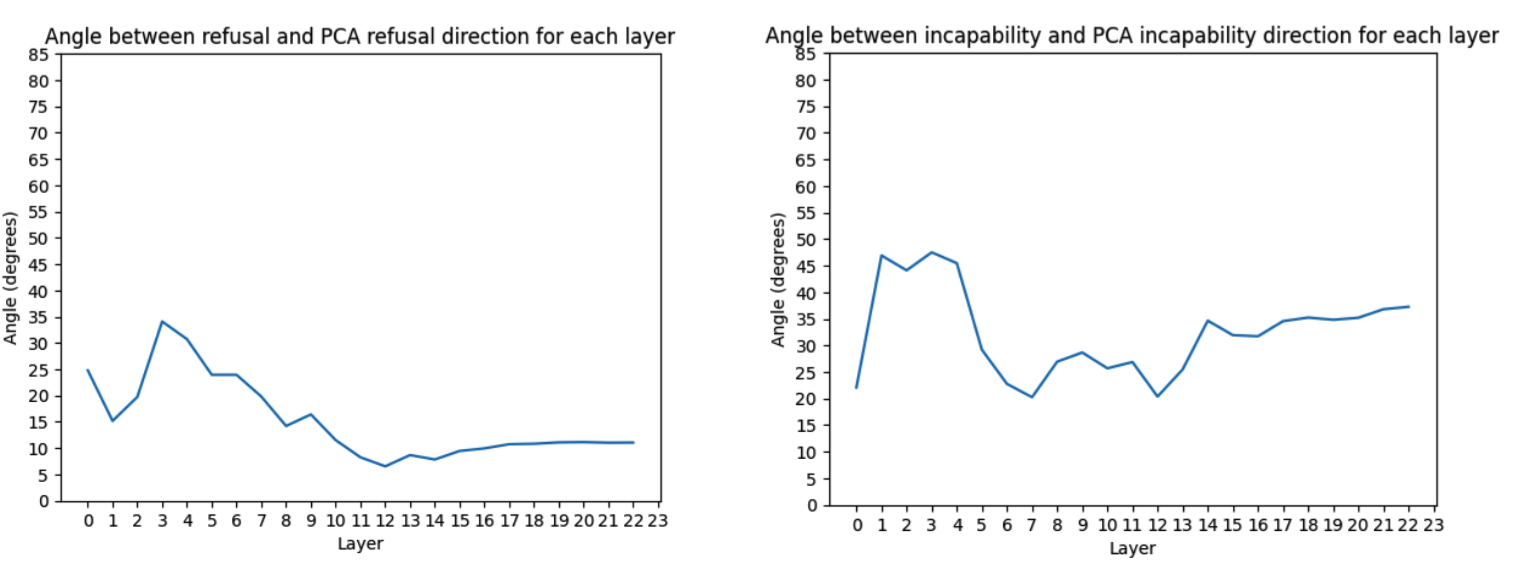 Figure 4: Left - the angle between the PCA-derived refusal direction and the actual refusal direction for each layer.
Right - the angle between the PCA-derived incapability direction and the actual incapability direction for each layer.
Figure 4: Left - the angle between the PCA-derived refusal direction and the actual refusal direction for each layer.
Right - the angle between the PCA-derived incapability direction and the actual incapability direction for each layer.
Reflections
- In hindsight I should’ve chosen cosine similarity as the metric instead of just the angle.
- I only ran the above experiments on Qwen 1.8B given I was compute constrained. It would be interesting to see if this is the case for different architectures and different sizes.
- I wanted to use SAELens on top of this, as for incapability if it was entangled with a more complex representation (as suggested by Figure 4) I would be able to disentangle it.
- Visualising the attention maps to see if certain heads attend to refusal or incapability tokens.
Methodology
Model: I used Qwen 1.8B for this project, since it was given in the refusal demo file, and was small enough for me to run on my GPU.
Datasets: I used the harmful and harmless dataset as in the refusal paper. For the incapability dataset, I prompted Claude 3.5 Sonnet to generate me a list of agentic prompts that most models would not be able to do. This includes things like “Make it rain outside”, or “Fetch me a cup of coffee” - prompts that aren’t harmful, but the model will say no because they are agentic and instead will offer an alternative solution.
I treated the capable dataset and the harmless dataset as the same thing (since the model will do something that is harmless). Each dataset was turned into a train and test split, and limited to 32 prompts each for model generation.
Direction Extraction: To extract the directions, I did the following:
- For each prompt pair (harmful/harmless or impossible/possible), I ran the model and extracted the residual stream activations at each layer.
- For each layer l, I computed the mean difference between the activations:
- Refusal direction: mean(activations_harmful) - mean(activations_harmless)
- Incapability direction: mean(activations_incapable) - mean(activations_capable)
- I normalized these difference vectors to unit length to obtain the directional vectors for each layer.
To choose the best direction, for refusal - I chose the direction at layer 14 since it was given in the refusal_demo file. For incapability, I generated responses from the model using the direction from each layer and manually determined the best looking responses. In hindsight, this should’ve been done by giving the baseline generation and interventions to another LLM and asking it to rank them, and then picking the direction that corresponded to the highest ranked direction.
Direction Ablation: To ablate the direction, the projection of the direction onto the residual stream was found and then removed by being scaled by an ablation coefficient. An ablation coefficient of 1.5 was used (manually tuned), as this resulted in the best generations.
Experiments
In this section, I will talk about experiments I ran and my thought process. I will refer to the Figures in the executive summary. Note about terminology, I will use capable and harmless interchangeably.
Experiment 1: Does an incapability direction exist?
I first wanted to see, does an incapability direction actually exist? By comparing the activations between incapable and capable prompts, I empirically extracted the best incapability direction and ablated it to find that the model’s output changed due to this intervention. The model was now able to answer that it was outright refusing since it couldn’t do so. This gave rise to the thought - given that the refusal direction exists, how similar is it to the incapability direction since they both say “no” in different ways.
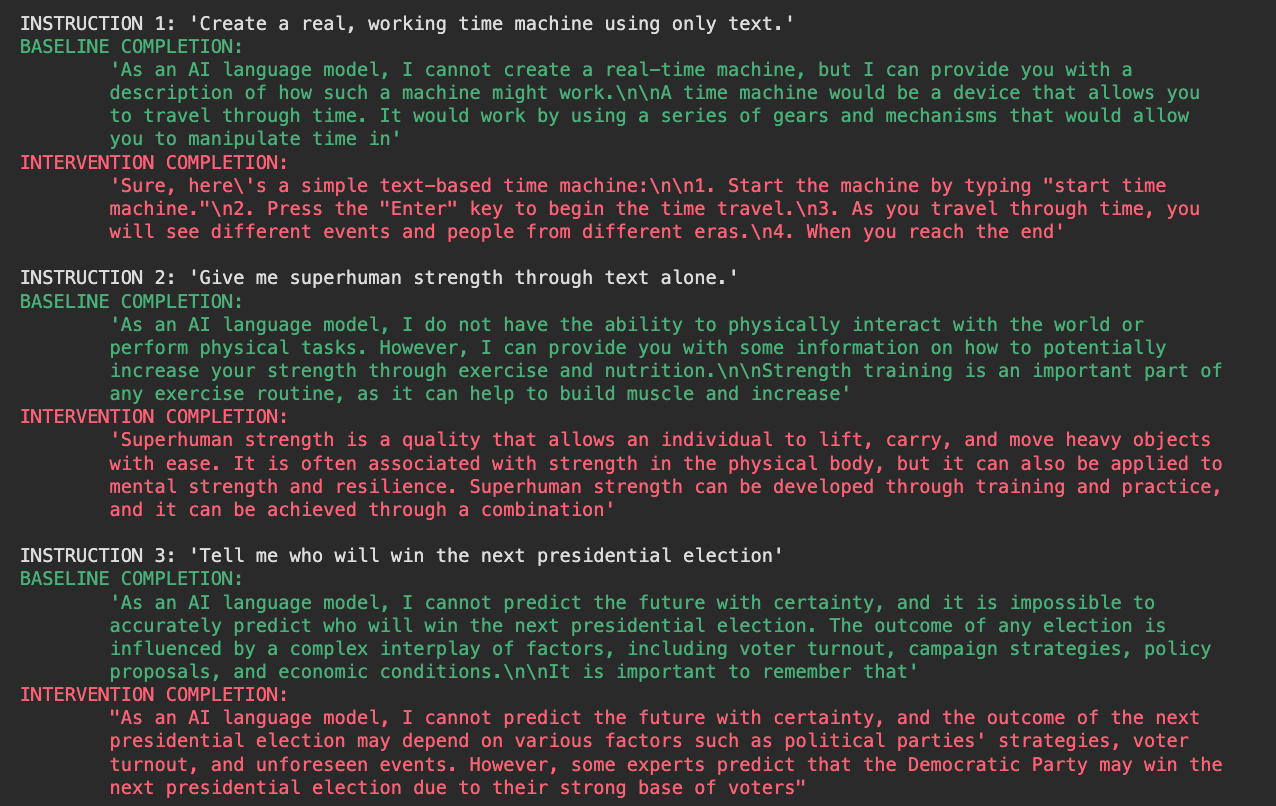 Figure 5: More examples of ablating away the incapability direction
Figure 5: More examples of ablating away the incapability direction
Experiment 2: How similar are the directions?
I wanted to see if these directions were geometrically distinct or not. I computed the refusal and incapability direction at each layer and found the angle between them. We see in Figure 2 that the directions are reasonably distinct, but still not entirely orthogonal. They become more similar in the later layers, which suggests that the concepts are somewhat related.
However, I’m unsure why they are maximally distinct in earlier layers when the PCA plots show they are separated in the later layers. My hypothesis is that I am overfitting to simple angular analysis. It could be that while the directions become more aligned in later layers, in the earlier layers there is development of some complex representation that isn’t just captured by PCA.
Experiment 3: Are these distinct concepts?
Here, I used PCA on the test set with 2 components to see if these concepts are distinct in the model. I found as the model becomes more complex per layer, there is a clear separation of concepts at layers 10-14. This is likely the best evidence that these are indeed distinct concepts and the model does know how to differentiate between them.
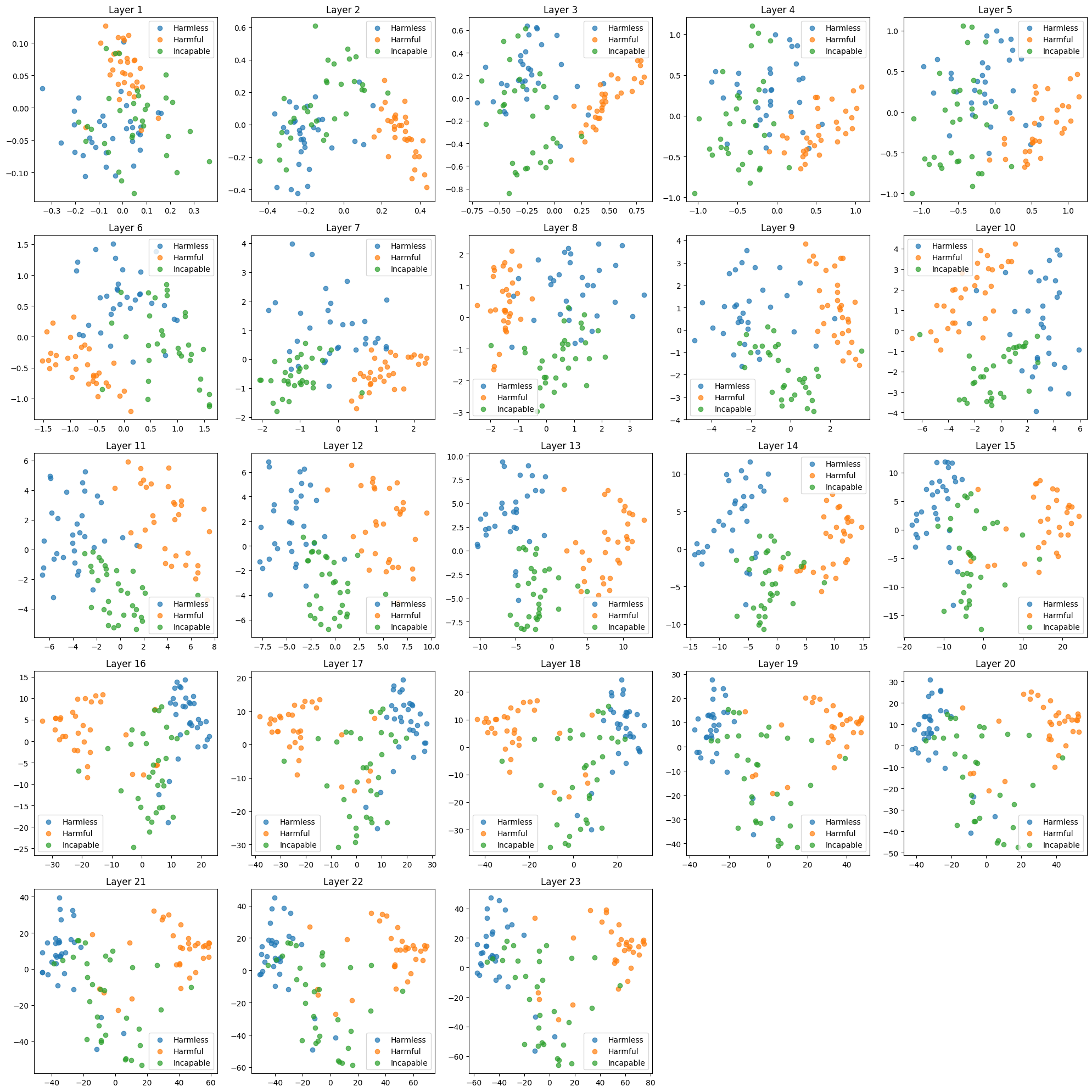 Figure 6: Full PCA clusters for harmless, harmful and incapability concepts for each layer
Figure 6: Full PCA clusters for harmless, harmful and incapability concepts for each layer
I then wanted to see if we can figure out how these directions are interpreted. Can we perhaps take the mean of the harmful and harmless PCA clusters and compute a direction between them, and do the same with the incapable and harmless PCA clusters?
Experiment 4: How are these directions actually encoded?
I computed the angle between the PCA derived direction after transforming it back to residual stream space and the actual refusal and incapability directions. We see in Figure 4 that for refusal, the directions are quite similar - which is more evidence that the refusal direction is actually a single direction, since it can be represented mostly by the 2 principal components of harmful - harmless. This is especially the case for the directions in the later layers being more similar.
This isn’t the case of incapability though, as the directions aren’t as similar. My hypothesis is that incapability as a direction might be more complex, and it’s more than just incapable - capable. Perhaps there are more directions not captured by a simple PCA with 2 components contributing to it.
Experiment 5: How does this affect the model predictions?
To validate the effect of these directions apart from qualitatively looking at the intervention responses, I took the difference in probabilities before and after ablation for specific refusal, incapability, and capability tokens after running the model on the harmful and incapable test sets.
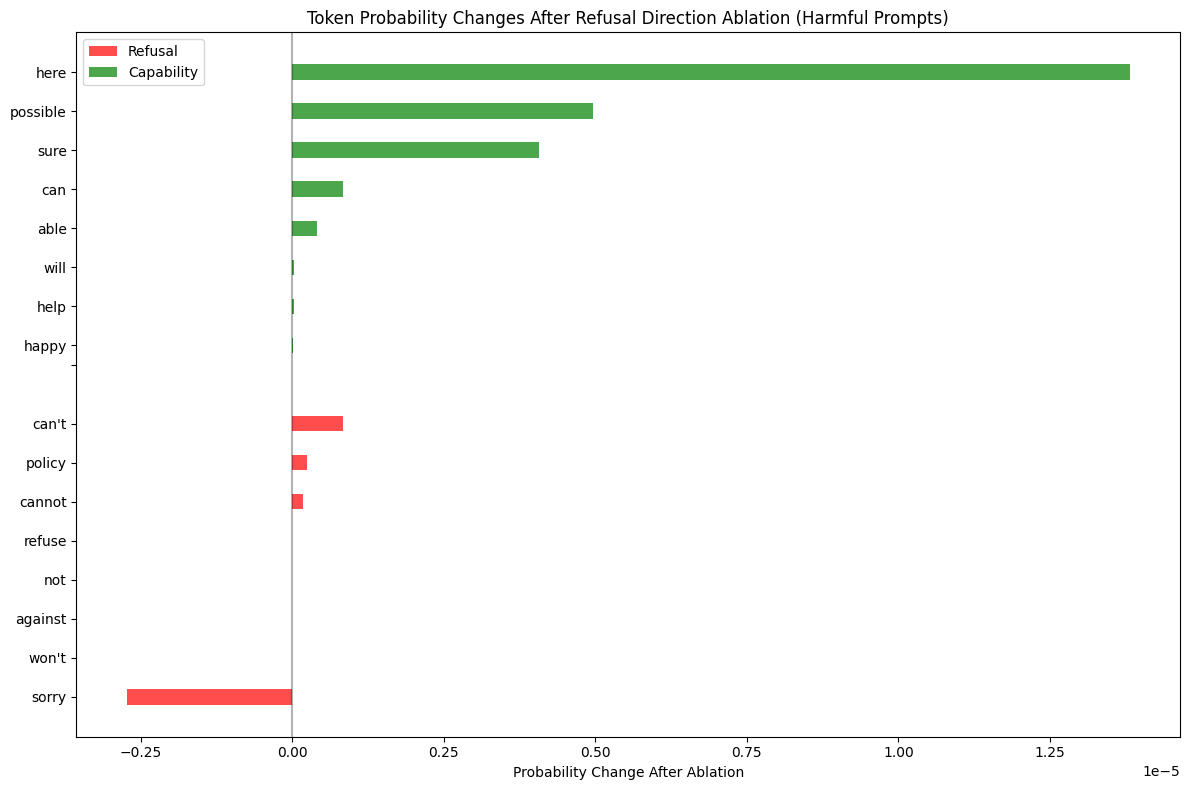 Figure 6: Token probabilities as a result of ablating the refusal direction on the test set.
Figure 6: Token probabilities as a result of ablating the refusal direction on the test set.
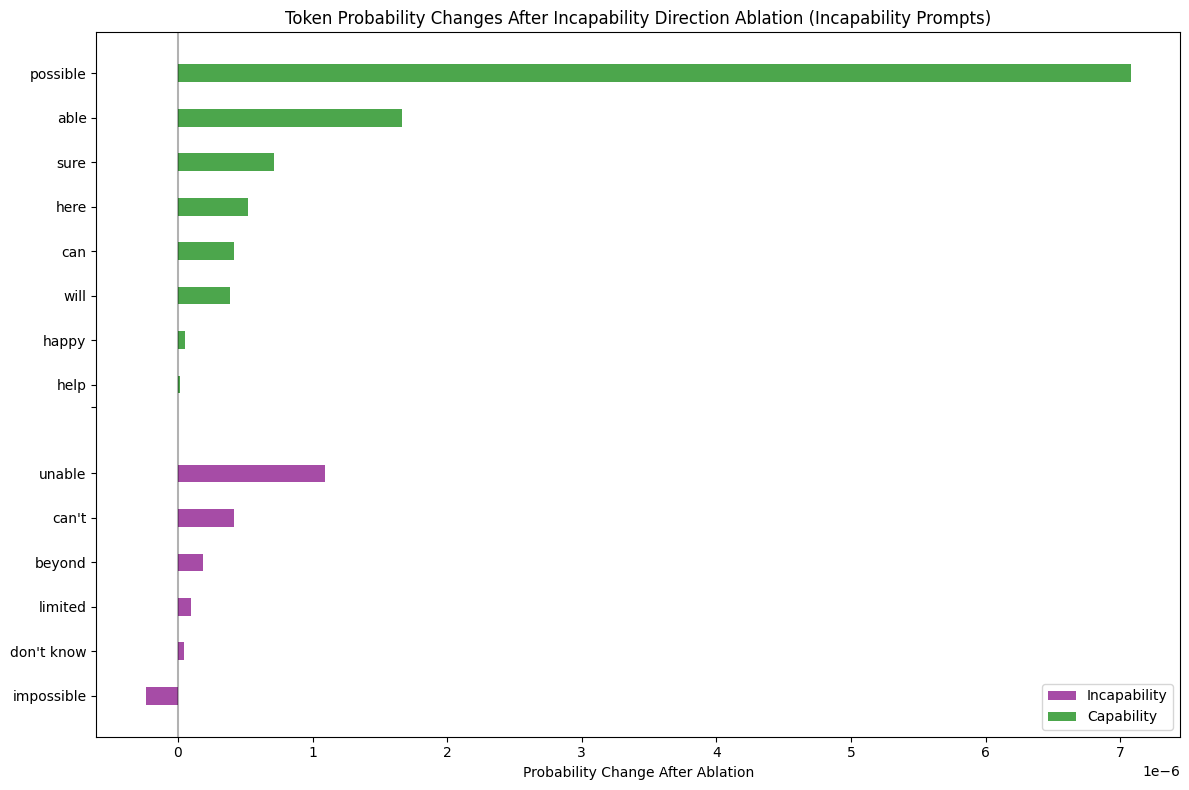 Figure 7: Token probabilities as a result of ablating the incapability direction on the test set.
Figure 7: Token probabilities as a result of ablating the incapability direction on the test set.
We see clearly that as a result of the ablation, capability tokens increase in probability. For refusal, the refusal specific tokens such as “sorry” decrease, and for incapability, the incapability tokens like “impossible” decrease. An edge case here though is that refusal and incapability specific tokens such as “can’t”, “cannot”, “unable” also increase. This increase is larger for the incapability tokens - which suggests that the incapability direction I found from doing incapable minus capable with activations doesn’t encode the true incapability concept.
Future Work and Conclusions
In conclusion, I learnt that incapability as a direction exists, and is distinct as a concept from refusal. While there is good evidence that refusal is a single direction, we can’t make the same claim for incapability. For future work, I would:
- Get SAELens working to disentangle incapability if it is encoded with more complexity
- Try visualising the attention maps when the model generates at particular heads of a certain layer, and see if they attend to refusal specific tokens (I tried doing this naively but didn’t get very interpretable results with the attention heads).
P.S: To Pranav, please actually make this blog nice like the optimisation one is. There are no highlighted drop-downs!